

PQA is an acronym for Performance Quality Assurance. We developed PQA to answer the questions, which APL primitives have slowed down from one build of the Dyalog interpreter to the next, and by how much? Currently, PQA consists of 13,659 benchmarks divided into 136 groups.




The Graphs
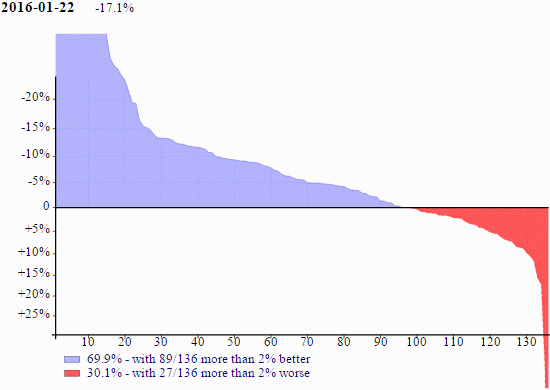
The graph above (and all other graphs in this article) plot the timing ratios between version 14.1 and the build of version 15.0 on 2016-01-22, the Windows 64-bit Unicode version. The data are the group geometric means. The horizontal axis are the groups sorted by the means. The vertical axis are logarithms of the means. The percent at the top (-17.1%) indicates that over all 136 groups, version 15.0 is 17.1% faster than version 14.1. The bottom of the graph indicates how many of the groups are faster (blue, 69.9%) and how many are more than 2% faster (89/136); and how many are slower (red, 30.1%) and how many are more than 2% slower (27/136).
For the graph above, the amount of blue is gratifying but the red is worrying. From past experience the more blue the better (of course) but any significant red is problematic; speed-ups will not excuse slow-downs.
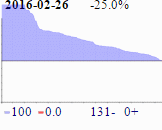
PQA is run nightly when a new build of version 15.0 is available. Each PQA run takes about 12.5 hours on a dedicated machine. The graphs from the past month’s runs are presented on the strip on the right; the first of them is a shrunken version of the big graph at the beginning of the article.
Challenges
About two years ago, investigations into a user report of an interpreter slow-down underscored for us a “feature” of modern computer systems: An APL primitive can run slower even though the C source is changed only in seemingly inconsequential ways and indeed even unchanged. Moreover, the variability in measurements frequently exceeded the difference in timings between the two builds, and it was very difficult to establish any kind of pattern. It got to the point where even colleagues were doubting us — how hard can it be to run a few benchmarks?
- The system is very noisy.
- Cache is king.
- The CPU acts like an interpreter.
- Branching (in machine code) is slow.
- Instruction counts don’t tell all.
- The number of combinations of APL primitives and argument types is enormous.
What can be done about it?
- Developed PQA.
- Run PQA on a dedicated machine.
- Make the system as quiet as possible, then make it quieter than that. 🙂
- Set the priority of the APL task to be High or Realtime.
- The
⎕aior⎕tsclocks have insufficient resolution. UseQueryPerformanceCounteror equivalent. The QPC resolution varies but is typically around0.5e¯6seconds. - Run each benchmark expression enough times to consume a significant amount of time (
50e¯3seconds, say). - Repeat the previous step enough times to get a significant sample.
Despite all these, timing differences of less than 5% are not reliably reproducible.
Silver Bullets
Given the difficulties in obtaining accurate benchmarks and given the amount of time and energy required to investigate (phantom) slow-downs, there evolved among us the idea of “silver bullets”: We will actively work on speed-ups instead of waiting for slow-downs to bite.
The speed-ups to be worked on are chosen based on:
- decades of experience in APL application development
- decades of experience in APL design and implementation
- APLMON snapshots provided by users
- talking to users
- interactions on the Dyalog Forums
- running benchmarks on user applications
- user presentations at Dyalog User Meetings
- the speed-up is easy, while mindful of Einstein’s admonition against drilling lots of holes where the drilling is easy
We were gratified to receive reports from multiple users that their applications, without changes, sped up by more than 20% from 13.2 to 14.0. A user reported that using the key operator in 14.0 sped up a key part of their application by a factor of 17. Evidently some of the silver bullets found worthwhile targets.
We urge you, gentle reader, to send us APLMON snapshots of your applications, to improve the chance that future speed-ups will actually speed up your applications. APLMON is a profiling facility that indicates which APL primitives are used, how much they are used, the size and datatype of the arguments, and the proportion of the overall time of such usage. An APLMON snapshot preserves the secrecy of the application code.
We will talk about the new silver bullets for version 15.0 in another blog post. Watch this space.
Coverage
We look at benchmarks involving + as a dyadic function to give some idea of what’s being timed. There are 72 such expressions. Variables with the following names are involved:
'xy'∘.,'bsildz'∘.,'0124'
┌───┬───┬───┬───┐
│xb0│xb1│xb2│xb4│
├───┼───┼───┼───┤
│xs0│xs1│xs2│xs4│
├───┼───┼───┼───┤
│xi0│xi1│xi2│xi4│
├───┼───┼───┼───┤
│xl0│xl1│xl2│xl4│
├───┼───┼───┼───┤
│xd0│xd1│xd2│xd4│
├───┼───┼───┼───┤
│xz0│xz1│xz2│xz4│
└───┴───┴───┴───┘
┌───┬───┬───┬───┐
│yb0│yb1│yb2│yb4│
├───┼───┼───┼───┤
│ys0│ys1│ys2│ys4│
├───┼───┼───┼───┤
│yi0│yi1│yi2│yi4│
├───┼───┼───┼───┤
│yl0│yl1│yl2│yl4│
├───┼───┼───┼───┤
│yd0│yd1│yd2│yd4│
├───┼───┼───┼───┤
│yz0│yz1│yz2│yz4│
└───┴───┴───┴───┘
x and y denote left or right argument; bsildz denote:
bsildz |
boolean short integer integer long integer double complex |
1 bit 1 byte 2 bytes 4 bytes 8 bytes 16 bytes |
0124 denote the base-10 log of the vector lengths. (The lengths are 1, 10, 100, and 10,000.)
The bsil variables are added to the like-named variable with the same digit, thus:
xb0+yb0 xb0+ys0 xb0+yi0 xb0+yl0
xs0+yb0 xs0+ys0 xs0+yi0 xs0+yl0
xi0+yb0 xi0+ys0 xi0+yi0 xi0+yl0
xl0+yb0 xl0+ys0 xl0+yi0 xl0+yl0
xb1+yb1 xb1+ys1 xb1+yi1 xb1+yl1
xs1+yb1 xs1+ys1 xs1+yi1 xs1+yl1
...
xi4+yb4 xi4+ys4 xi4+yi4 xi1+yl4
xl4+yb4 xl4+ys4 xl4+yi4 xl4+yl4
There are the following 8 expressions to complete the list:
xd0+yd0 xd1+yd1 xd2+yd2 xd4+yd4
xz0+yz0 xz1+yz1 xz2+yz2 xz4+yz4
The idea is to measure the performance on small as well as large arguments, and on arguments with different datatypes, because (for all we know) different code can be involved in implementing the different combinations.
After looking at the expressions involving+, the wonder is not why there are as many as 13,600 benchmarks but why there are so few. If the same combinations are applied to other primitives then for inner product alone there should be 38,088 benchmarks. (23×23×72, 23 primitive scalar dyadic functions, 72 argument combinations.) The sharp-eyed reader may have noticed that the coverage for + already should include more combinations:
xb0+yb1 xb0+yb2 xb0+yb4
xb0+ys1 xb0+ys2 xb0+ys4
xb0+yi1 xb0+yi2 xb0+yi4
xb0+yl1 xb0+yl2 xb0+yl4
...
xl0+yi1 xl0+yi2 xl0+yi4
xl0+yl1 xl0+yl2 xl0+yl4 We will be looking to fill in these gaps.
More on the Graphs
You should know that the PQA graphs shown here are atypical. The “blue mountain” is higher and wider than we are used to seeing, and it is unprecedented for a graph (the one for 2016-02-26) to have no red at all.
From version 15.0, the list of new silver bullets is somewhat longer than usual, but silver bullets usually only explain the blue peak. (Usually, speed-ups are implemented only if they offer a factor of 2 or greater improvement, typically achieved only on larger arguments.) What of the part from the “inflection point” around 30 and thence rightward into the red pit?
We believe the differences are due mainly to using a later release of the C compiler, Visual Studio 2015 in 15.0 vs. Visual Studio 2005 in 14.1. The new C compiler better exploits vector and parallel instructions, and that can make a dramatic difference in the performance of some APL primitives without any change to the source code. For example:
x←?600 800⍴0
y←?800 700⍴0
cmpx 'x+.×y' ⍝ 15.0
1.54E¯1
cmpx 'x+.×y' ⍝ 14.1
5.11E¯1(Not all codings of inner product would benefit from these compiler techniques. The way Dyalog coded it does, though.)
Together with improvements for specific primitives such as +.× the new C compiler also provides a measurable general speed-up. Unfortunately, along with optimizations the new C compiler also comes with pessimizations. (Remember: speed-ups will not excuse slow-downs.) Some commonly and widely used C facilities and utilities did not perform as well as before. Your faithful Dyalog development team has been addressing these shortcomings and successfully working around them. Having a tool like PQA has been invaluable in the process.
It has been an … interesting month for PQA from 2016-01-22 to 2016-02-27. Now it’s onward to ameliorating the red under Linux and AIX.
 Follow
Follow
My process is to react to points as they are presented, with editing if later parts of the post answer my reactions. Some reactions might not have been repaired when answers were found, (I am not a robot.)
. why are ‘group geometric means’ used?
. why are the 136 groupings given equal weight? what if _my_ application only uses blue groups, or even worse, red groups?
. would a line denoting the 2% show things? The x/y footnote might be best left as a line on the graph.
. some of the heights, at the left and right, seem truncated. how much data has been lost?
. what are the comparisons being made over? a: day-to-day? b:current v last release? Answer: b
. the x-axes are at best permutations of each other. I hope the tool has something to normalize the x-axis so single day effects can be pinpointed.
• why are ‘group geometric means’ used?
The data are ratios and geometric means give a fairer picture than arithmetic means.
• why are the 136 groupings given equal weight? what if _my_ application only uses blue groups, or even worse, red groups?
There is no way to have a representative sample of all applications of all users, and yes you are screwed if you happened to use “red groups” extensively. PQA is meant to detect _any_ red for remedial action. As well, as the article states, send us APLMON snapshots of your applications to improve the chance that future speed-ups will actually speed up your applications.
• would a line denoting the 2% show things? The x/y footnote might be best left as a line on the graph.
For now, we are satisfied with the current arrangements.
• some of the heights, at the left and right, seem truncated. how much data has been lost?
The graphs are indeed truncated in the vertical axis. The point is, if a group is more than 25% faster then we are content, and if it is more than 25% slower then we need to do _something_, and it doesn’t much matter whether it’s 30% slower or 80% slower.
• the x-axes are at best permutations of each other. I hope the tool has something to normalize the x-axis so single day effects can be pinpointed.
We find that the current arrangement (sorted groups) works best for giving an overall picture of the total performance, and a good picture of the improvement or deterioration over time. Single day effects are often less interesting due to the vagaries of benchmarking.
PQA reports contain much more information than what is possible to show in a blog post. They include a “drill down” capability for answering more detailed enquiries.
Thank you for your comments/questions.