

Last week the ‘bots were busy preparing for the J Language Conference in Toronto, where they made their first public appearance together. Upon returning to Bramley they continued training and we are proud to present the first recording of their new dance:
The ‘bots are both running the same DyaBot class as last year. This class exposes a property called Speed, which is a 2-element vector representing the speed of the right and left wheels respectively. Valid values range from +100 (full speed ahead) to -100 (full reverse). The annotations displayed at the top left show the settings used for each step of the dance.
Controlling Two Robots at Once using Isolates
Isolates are a new feature included with Dyalog version 14.0, designed to make it easy to perform distributed processing. In addition to making it easy to used all the cores on your own laptop or workstation, isolates make it possible to harness the power of other machines. This requires the launching of an “isolate server” on each machine that wants to offer its services:
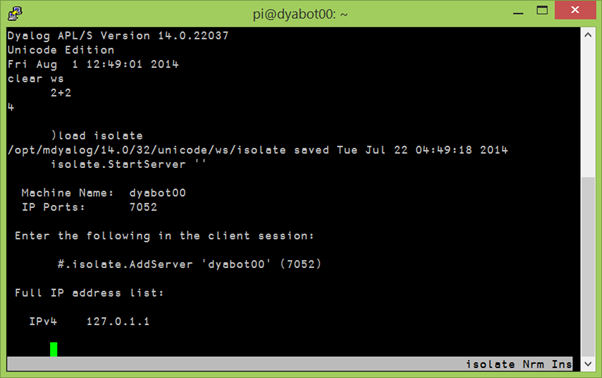
Starting an isolate server on DyaBot00 using PuTTY.
Once we have an isolate server running on each robot we can take control of them from a remote session as follows:
)load isolate
#.isolate.AddServer 'dyabot00' (7052)
#.isolate.AddServer 'dyabot04' (7052)
bots←isolate.New¨Bot Bot
bots.Init
dyabot00 dyabot04Above, we create two instances of the Bot namespace. The expression Bots.Init invokes the Init function, which returns the hostname, in each isolate:
:Namespace Bot
∇ r←Init;pwd
pwd←∊⎕SH'pwd' ⍝ Find out where to copy from
#.⎕CY botws←pwd,'/DyaBot/DyaBot.dws' ⍝ copy ws
i←⎕NEW #.DyaBot ⍬ ⍝ Make DyaBot instance
r←⎕SH'hostname' ⍝ Return hostname
∇
:EndNamespaceNext, we define a function “run” that will take a vector of dance steps as input. Each step is a character vector (because that makes editing slightly easier!) containing five numbers: The first two set the speed of one robot, the next two the speed of the other and the fifth defines the duration of the step. After each step we pause for a second, to give humans time to appreciate the spectacle:
∇ run cmds;data;i;cmd;z
[1] ⎕DL 5
[2] :For i :In ⍳≢cmds
[3] :If ' '∨.≠cmd←i⊃cmds
[4] data←1 0 1 0 1⊂2⊃⎕VFI cmd ⍝ Cut into 3 numeric pieces
[5] z←bots.{i.Speed←⍵}2↑data ⋄ ⎕DL⊃¯1↑data ⋄ z←bots.(i.Speed←0)
[6] ⎕DL 1
[7] :EndIf
[8] :EndFor
∇
Now we are ready to roll: Call the run function with a suitable array and watch the robots dance (see the video at the top)!
↑choreography50 50 0 0 1.5 0 0 50 60 1.2 50 ¯50 50 ¯50 0.3 20 80 10 70 5 50 ¯50 50 ¯50 0.3 50 50 0 0 1.5 0 0 50 60 1.2dance choreography
Join us again next week to hear what happened when Romilly came to Bramley to help wire up the accelerometer and gyro!
 Follow
Follow