

Blog post from presentation by Dr. Markos Mitsos – Deutsche Krankenversicherung AG DKV – ERGO, Actuarial Department @ Dyalog ’15.
by Vibeke Ulmann
DKV has many million health insurance contracts. Each tariff of each contract has to be checked and possibly adjusted annually in terms of insurance premium based on a number of criteria – without imposing undue ‘financial’ hardship on the Insured individual. Dr. Mitsos is in the process of migrating the simulation modelling into Dyalog APL.
The German Healthcare system is unlike any other in the world. If you earn more than € 45,000 per annum you can choose between the Government Healthcare scheme or draw up a private health insurance. If you are in the state health system you have the option of adding private health insurance on top.
There is legislation in place to ensure that Health insurance companies do not calculate premiums arbitrarily. When entering into a contract the tariff for your health insurance is calculated such that it stays the same over your lifetime. This means that young people pay more than the insurance needs to cover their healthcare expenses whereas older persons are drawing on the reserves that has been saved for them.
The two illustrations below show examples of contract lifetimes
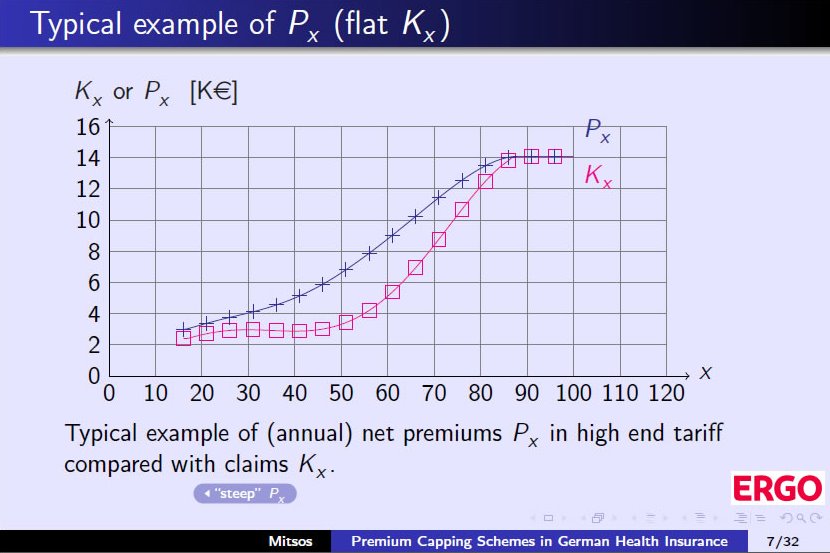
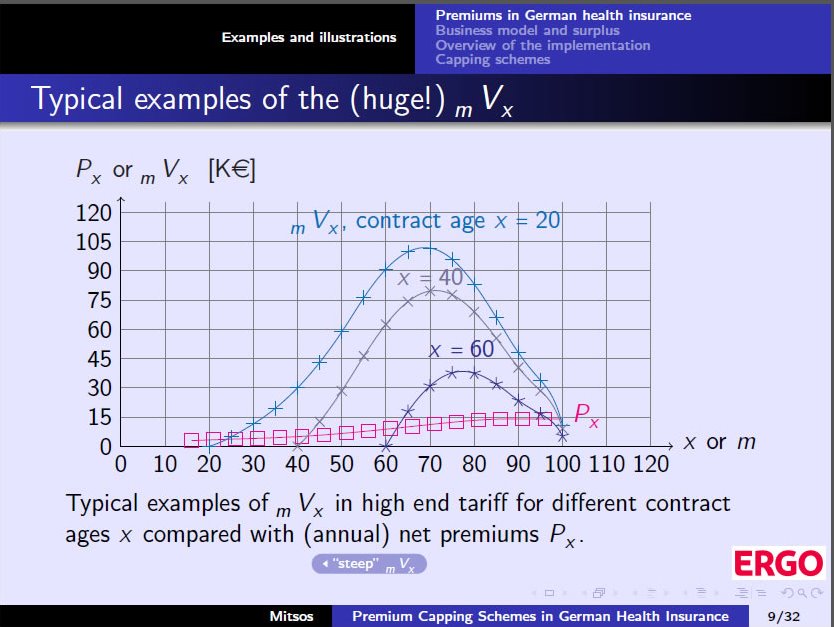
With millions of contracts DSV has Billions of Euro in reserve which they have to manage to the best of their ability. 90% of the proceeds from fund management plus unspent security fees of 5% on each contract has to be paid back to the insurance holders within 3 years and how this is done is the only area where the insurance company has a little freedom to decide how to best distribute the surplus (the socalled “war chest”) to the insurance holders.
If the premium recalculation shows that some contracts need to have a huge premium increase, DKV, can use part of the ‘war chest’ to help fund (read cap off) this increase after agreement with an independent Trustee. (Unabhäniger Treuhänder)
The actuary department of DKV – undertakes simulated calculations on the costs of the capping schemes. The results go to the Executive Board of ERGO and they go to the Chief Actuary in DKV, who is personally liable for the adjustments being in line with the taxation rules, the legislation, and that it is reasonable to impose a premium adjustment accordingly to each individual contract. The final sign off is done by the independent Trustee and then they are implemented into production.
The calculations are typically done on chuncks of around 1 million contracts, and although the maths is ‘simple’ in Actuary terms, the number crunching is massive – thus rendering APL a fast and precise modelling tool for ERGO.
In the ‘old’ days a simulation modelling calculation used to take days. However, according to Dr. Mitsos the simulation calculation done in APL takes mere minutes – and ERGO is looking into further speeding it up. The actual figures are presented in Excel, and it’s the posting of the number to Excel which actually takes up most of the time.
My main take away from this brilliant presentation – and subsequent conversation over lunch – is the absolutely fantastic number of complex assumptions which have to go into simulating the annual checks and recalculations for premium increases. This becomes especially impressive when you take into consideration that the German Government does NOT allow the Insurance companies to make any forward projections on how they assume/expect a contract will develop in terms of claims over time. Everything has to be calculated ‘as the situation is’ in the year in question.
The way the system is constructed is such that in order to make money as an insurance company you will have to service your customers well.
 Follow
Follow


 After lunch – instead of having a sleep inducing talk, Brian challenged us to build a website for a Big Brian’s Burger Bistro offering ordering facility for various products with side orders, and a dashboard to monitor the ordering, product category, speed of order processing, and – most importantly from a management point of view – keep an eye on revenue and which products generate most revenue, with auto update when new orders where processed and paid.
After lunch – instead of having a sleep inducing talk, Brian challenged us to build a website for a Big Brian’s Burger Bistro offering ordering facility for various products with side orders, and a dashboard to monitor the ordering, product category, speed of order processing, and – most importantly from a management point of view – keep an eye on revenue and which products generate most revenue, with auto update when new orders where processed and paid. We’re here, we’re excited and Naxos greeted us with sweltering temperatures and beautiful sunshine on Saturday. Being the oldest Greek settlement in Sicily, founded before Syracuse, around 735 BC, Naxos has a lot to offer. The Atahotel Naxos venue, where the user meeting is taking place, is situated right on the coast with a fantastic view to the impressive Mount Etna – by far the largest of Europe’s active volcanos.
We’re here, we’re excited and Naxos greeted us with sweltering temperatures and beautiful sunshine on Saturday. Being the oldest Greek settlement in Sicily, founded before Syracuse, around 735 BC, Naxos has a lot to offer. The Atahotel Naxos venue, where the user meeting is taking place, is situated right on the coast with a fantastic view to the impressive Mount Etna – by far the largest of Europe’s active volcanos. You will find more detailed blog posts from a couple of today’s workshops:
You will find more detailed blog posts from a couple of today’s workshops:{kind=link}