Arriving to meet the warm sea air is already a refreshing change as this year’s long, hot summer started to close in the weeks leading up to this year’s user meeting. Of course, for some with less far to travel, the warmth is a familiar comfort.
Apartments at the Real Marina in Olhão, Portugal
As delegates arrived on Sunday night we were treated to a lovely surprise – a birthday cake to celebrate Tony Corso’s birthday! Happy Birthday, Tony!
Today we kicked off the user meeting with workshops, giving delegates hands-on experience with a range of Dyalog offerings for application development.
Attendees of Rich Park and Rodrigo Girão Serrão’s language workshops explored different ways to express ideas in APL using both tried and true idioms in the morning and newer language features in the afternoon – they compared expressiveness and performance implications in difference circumstances.
Morten and Josh got participants up to speed with using and maintaining code which lives outside of your workspace in text files, while Richard Smith and Bjørn Christensen showed how to manage and interact with data from outside of the workspace.
Brian Becker guided delegates into the world of SAAS (Software As A Service). It is encouraging to see how straightforward having APL code talk to the outside world can be. As usual, however, the complexities reveal themselves as you delve deeper in to specific use cases and circumstances.
Morten and Josh show how to store source code as text files using Link
Without a doubt, getting to meet our users face to face has already proved to be the greatest enjoyment of the meeting so far. Some familiar faces long since last seen, and others only over a screen. Discussing ideas face to face still retains a value impossible to quantify.
Overall a fantastic beginning to the week and we cannot wait to experience the rest of this week!
As part of the bigger, overarching refactoring goal of making Py’n’APL great again, I refactored some of the code that deals with sending data from Python to APL and receiving data from APL into Python. In this blog post, I will describe – to the best of my abilities – how that part of the code works, how it differs from what was in place, and why those changes were made.
The starting point for this blog post is the commit b7d4749.
If you are going to refactor a working piece of code, the first thing you need to do is to make sure that you know what the code is doing! This will help to ensure that your refactoring does not break the functionality of the code. With that in mind, I started working my way through the code.
I started by looking at the file ConversionInterface.py and the two classes Sendable and Receivable that were defined in there. By reading the comments, I understood that these two classes were defining the “conversion interface”. In this context, the word “interface” has approximately the Java meaning of interface: it defines a set of methods that the classes that inherit from these base classes have to implement. For the class Sendable, there are two methods toJSONDict and toJSONString; and for the class Receivable, there is one method to_python.
Even though I had just started, I already had a couple of questions:
Do the names Sendable and Receivable mean that these objects will be sent to/received from APL or from Python respectively?
Why is there a comment next to the definition of Sendable that says that classes that implement a method from_python will inherit from Sendable? Is that a comment that became a lie as the code evolved? If not, why isn’t there a stub for that method in the class itself?
The more I pondered on these questions, the more I started to think that the “conversion interface” isn’t necessarily about the sending to/receiving from APL, but rather the conversion of built-in Python types to helper classes like APLArray or APLNamespace (from the file Array.py) and back. So, it might be that Sendable and Receivable are supposed to be base classes for these helper classes, telling us which ones can be converted to/from built-in Python types. I needed to solve this conundrum before I could prepare these two base classes and use Python mechanisms to enforce these “interfaces”.
What the Interface Really Means
After playing around with the code a bit more, I felt more confident that Sendable should be inherited by classes that represent things that can be sent to APL and Receivable represents things that can be received from APL. However, it must be noted that Py’n’APL doesn’t send Python built-in types directly to APL. Whenever we want to send something to APL, Py’n’APL first converts it to the suitable intermediate (Python) class. For example, lists and tuples are converted to APLArray, and dictionaries are converted to APLNamespace.
If an APLArray instance is supposed to be sendable to APL, we must first be able to build it from the corresponding Python built-in types, and that is why almost all Sendable subclasses also implement a method from_python. Looking at it from the other end of the connection, Receivable instances come from APL and Py’n’APL starts by taking the JSON and converting it into the appropriate APLArray instances, APLNamespace instances, etc. Only then can we convert those intermediate representations to Python, and that is why all Receivable subclasses come with a method to_python. In addition, those Receivable instances come from APL as JSON, so we need to be able to instantiate them from JSON. That is why Receivable subclasses also implement a method fromJSONString, although that is not defined in the Receivable interface.
So, we have established that APL needs to know how to make sense of Python’s objects and Python needs to know how to make sense of APL’s arrays. (In Python, everything is an object, and in APL, everything is an array. In less precise – but maybe clearer – words, Python needs to be able to handle whatever APL passes to it, and APL needs to be able to handle whatever Python passes to it.) To implement this, we need to determine how Python objects map to APL arrays and how APL arrays map to Python objects. This is not trivial, otherwise I wouldn’t be writing about it! Here are two simple examples showing why this is not trivial:
Python does not have native support for arrays of arbitrary rank.
APL does not have a key-value mapping type like Python’s dict.
To solve the issues around Python and APL not having exactly the same type of data, we create lossless intermediate representations in both host languages. For example, Python needs to have an intermediate representation for APL arrays so that we can preserve rank information in Python. When possible, intermediate representations should know how to convert into the closest value in the host language. For example, the Python intermediate representation of a high-rank APL array should know how to convert itself into a Python list.
I began by looking at the handling of APL arrays and namespaces. These are the conversions that need to be in place:
APL arrays ←→ Python lists
APL arrays ← arbitrary Python iterables
APL namespaces ←→ Python dictionaries
When sending data from the Python side, it first needs to be converted into an instance of the appropriate APLProxy subclass. For example, a dictionary will be converted into an instance of APLNamespace. That object is converted to JSON, which is then sent to APL. APL receives the JSON and looks for a special field __extended_json_type__, which identifies the type of object. In this example, that is "APLNamespace". APL then uses that information to decode the JSON data into the appropriate thing (a namespace in this example).
When sending data from the APL side, a similar thing happens. First, the object is converted into a namespace that ⎕JSON knows how to handle. For example, an array becomes a namespace with attributes shape (the shape of the original array) and data (the ravel of the original array); the namespace is tagged with an attribute __extended_json_type__, which is a simple character vector informing Python what the object is. That namespace gets converted to JSON with ⎕JSON, and the JSON is sent to Python. Python receives the JSON and decodes it into a Python dictionary. Python then uses __extended_json_type__ to determine the actual object that the dictionary represents (an array, in our example) and uses the information available to build an instance of the appropriate APLProxy subclass (APLArray in this example).
Github commit 40523b9 shows one initial implementation of the APL code that takes APL arrays and namespaces and converts them into namespaces that ⎕JSON can handle and that Python knows how to interpret. This commit also shows the APL code for the reverse operation. For now, this APL code lives in the file Proxies.apln and the respective Python code lives in the file proxies.py. Everything is ready for me to hook this into the Py’n’APL machinery so that Py’n’APL uses this mechanism to pass data around…but that’s for another blog post!
Summary of Changes
GitHub’s compare feature shows all the changes I made since the commit that was the starting point for this post. The most notable changes are:
Moving the contents of ConversionInterface.py and ObjectWrapper.py into Array.py.
Adding the file proxies.py that will have the Python code to deal with the JSON and conversions, which will end up replacing most of the code I mentioned in the previous bullet point.
Adding the file Proxies.apln that will have the APL code to deal with the JSON and conversions, which will end up replacing a chunk of code that currently lives in Py.dyalog, which is a huge file with almost all of the Py’n’APL APL code.
Py’n’APL is an interface between APL and Python that allows you to run Python code from within APL and APL code from within Python. This interface was originally developed by Dyalog Ltd intern Marinus Oosters, who presented it in a webinar and at Dyalog ’17. I subsequently talked about Py’n’APL at Dyalog ’21, where I promised to update it and make it into an awesome and robust tool.
I’ve now stared at Py’n’APL’s code base for longer than I’m proud to admit, but without any proper goals and some basic project management this has been as effective in cleaning it up as a Magikarp’s Splash – in other words, it has had no effect.
For that reason, and in another attempt to take up the maintenance of Py’n’APL, I have decided to start blogging about my progress. This will be a way for me to share with the world what it feels like to take up the maintenance of a project that you aren’t necessarily very familiar with.
(By the way, Py’n’APL is open source and has a very permissive licence. This means that, like me, you can also stare at the source code; it also means that you can go to GitHub, star the project, fork it, and play around with it!)
Tasks
There are some obvious tasks that I need to do, like testing Py’n’APL thoroughly. This will help make Py’n’APL more robust, it will certainly uncover bugs, and it will help me to document Py’n’APL capabilities. The Python side will be tested with pytest and the APL side will be tested with CITA, which is a Continuous Integration Tool for APL.
The code base also needs to be updated. Py’n’APL currently supports Python 2 up to Python 3.5. At the time of writing this blog post, Python 2 has been in end-of-life for more than 2 years and Python 3.7 is reaching end of life in a couple of months. In other words, there is no overlap between the original Python versions supported and the Python versions that an application should currently support. In addition, Dyalog has progressed from v16.0 to v18.2, and the new tools available with the later versions are also likely to be useful.
Another big thing that should be done (and that would pay high dividends) is to update the project management of the Python part of Py’n’APL. By using the appropriate tooling, we make it easier to clone the (open source) repository so that others can poke around, play with it, modify it, and/or contribute.
The First Commits
Let GitHub commit 4283176f4ffd7f1067f216c1459306cdbc49189a be the starting point of my documented journey. At this point in time, I have two handfuls of commits on the branch master that fixed a (simple) issue with a Python import and added the usage examples I showed at Dyalog ’21. So, what will my first commits look like?
Setting up Poetry
The first thing I decided to do was to set up Poetry to manage the packaging and dependencies of the Python-side of code. By using Poetry, isolating whatever I do to/with the Python code from all the other (Python) things I have on my computer becomes trivial and it makes it very easy to install the package pynapl on my machine.
Auto-Formatting the Source Code
Another thing that I did was to use black (which I added as a development dependency to Poetry) to auto-format all the Python code in the repository. I imagine that this might sound surprising if you come from a different world! But if you look at the commit in question, you will see that although that commit was a big one, the changes were only at the level of the structure of the source code; by using a tool like black, I can play with a code base that is consistently formatted and – most importantly – that is formatted like every other Python project I have taken a look at. This consistency in the Python world makes it easier to read code, because the structure of the code on the page is always the same. This means that there is one less thing for my brain to worry about, which my brain appreciates!
In a typical Python project using black, or any other formatter, the idea is that the formatter is used frequently so that the code always has that consistent formatting style; the idea is not to occasionally insert an artificial commit that is just auto-formatting.
Fixing (Star) Imports
The other major minor change that I made was fixing (star) imports across the Python source code. Star imports look like from module_name import * and are like )LOADing a whole workspace in APL – you will gain access to whatever is inside the workspace you loaded. In Python, star imports are typically discouraged because after a star import you have no idea what names you have available, nor do you know what comes from where, which can be confusing if you star imported multiple modules. Instead, if you need the tools foo and bar from the module module_name, you should import the module and use the tools as module_name.foo and module_name.bar, or import the specific names that you need: from module_name import foo, bar.
I therefore went through the Py’n’APL Python source code and eliminated all the star imports, replacing them by the specific imports that were needed. (OK, not quite all star imports; the tests still need to be reworked.) As well as fixing star imports, I also reordered the imports for consistency and removed imports that were no longer needed.
Python 2-Related Low-Hanging Fruit
To get started with my task of removing old Python 2 code, I decided to start with some basic trimming. For example, there were plentyof instances where the code included conditional assignments that depended on the major version of Python (2 or 3) that were supposed to homogenise the code, making it look as much as possible like Python 3. I could remove those because I know we will be running Python 3. Another fairly basic and inconsequential change I could make was removing the explicit inheriting from object when creating classes (this was needed in Python 2, but not in Python 3).
Explicit Type Checking and Duck Typing
Python is a dynamically-typed language, and sometimes you might need to make use of duck typing to ensure that you are working with the right kind of objects. At Dyalog Ltd we are very fond of ducks, but duck typing is something else entirely:
If it walks like a duck and if it quacks like a duck then it must be a duck.
In other words, in Python we tend to care more about what an object can do (its methods) than what the object is (its type). The Py’n’APL source code included many occurrences of the built-in type and I went through them, replacing them with isinstance to implement better duck typing.
What Happens Next?
These are some of the main changes that I have made so far; they happen to be mostly inconsequential and all on the Python side of the code. Of course, I won’t be able to maintain Py’n’APL by only making inconsequential changes, so more substantial changes will come next. I also need to take a look at the APL code and see what can and what needs to be done there. Although I haven’t looked at the APL code as much as at the Python code, I have a feeling that I will not need to make as many changes there. Fingers crossed!
This blog post covers (approximately) the changes included in this GitHub diff.
On Tuesday 29 March we hosted APL Seeds ’22, the second annual online event for new and prospective users of APL (although everyone was welcome). Once again we were delighted to see that the majority of registrants had little to no APL experience; it feels like we get the chance to offer that same sense of discovery we felt when first learning about the language.
APL Seeds ’22 began with an introduction from Dyalog Ltd’s managing director, Gitte Christensen, in which she described her experiences of seeing APL enable people who had real problems to solve and showed some of what Dyalog provides in terms of the tools and interfaces that people might expect from a modern software development stack. Gitte explained the new Basic Licence, which is another step forward in Dyalog Ltd’s aim to bring APL to a wider audience. The Basic Licence allows non-commercial distribution of Dyalog along with APL-based solutions under the terms of the Royalty-Based Run-Time Licence, which will apply as the default run-time licence (see Prices and Licences for more information on Basic Licences). She also described some customer use cases, some of which might surprise newcomers to this language. Rich Park finished the introduction by pointing out where you can find more APL content, especially if you’re just getting started. For example, our tips for beginners includes things that might not be obvious when you first start the interpreter or read introductory books. The video description for the recording of this presentation contains many useful links!
Gitte opens the event with her thoughts on “What is APL?”, including the short expression 1 2 3 + 4 5 6 that started the journey which eventually brought her to Dyalog.
Rich then presented a basic introduction to APL, showing the benefits of a symbolic notation for programming as well as demonstrating how to put together simple building blocks to build a function. After introducing the basic syntax, right-to-left precedence, and the generality of APL operators, along with a handful of symbols including the famous outer product (⍺∘.F⍵) and array indexing (⍺[⍵]), he walked through constructing a function that visualised the probability distribution for sums of rolling two N-sided dice.
The Dist function uses just a handful of APL constructs to create a visualisation of a simple statistical distribution.
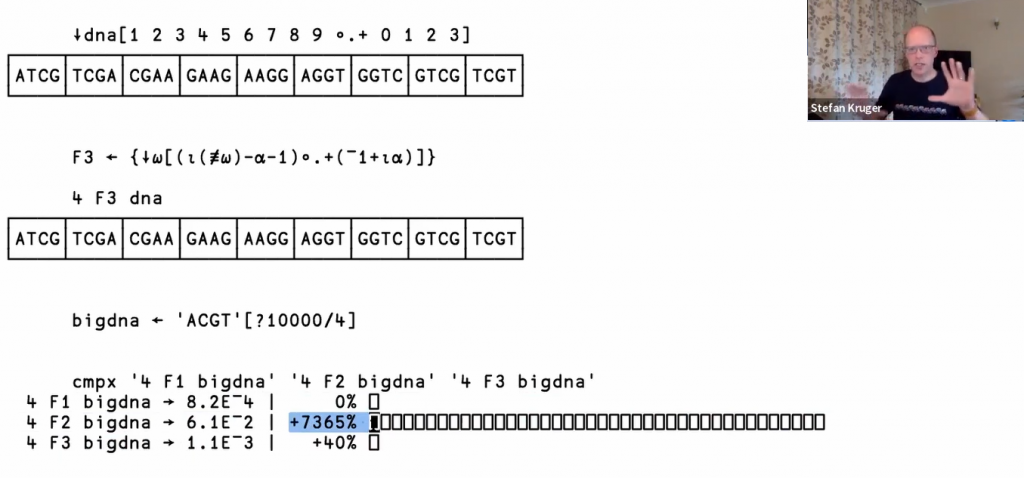
Stefan Kruger, author of the online book Learning APL, took us on an exploration of bioinformatics problems – a popular topic for the annual APL Problem Solving Competition. He described what a “k-mer” is (a chunk of DNA of a particular length), and compared different techniques for cutting up a text vector to isolate them from a DNA string, including a windowed-reduction (⍺F/⍵) and its generalised cousin, the stencil operator ((⍺⍺⌺⍵⍵)⍵), and our old friends the outer product and array indexing. Finally, Stefan looked at three approaches to doing some simple statistics in the Rosalind challenge “Computing GC Content“. To our delight, a new user who was in attendance commented that they learned new expressions and idioms that they had not seen before.
Stefan compares 3 functions to split a string into lengh-4 substrings
Andrew Sengul presented a more involved example, April. The April APL Compiler is a new entry in the APL field, compiling a subset of APL into the Common Lisp language and allowing APL functions to easily be used within Common Lisp programs. Andrew gave a concise history comparing Lisp and APL. He then gave a small introduction to using Lisp to write a “macro” (code that generates other code) before giving a glimpse into the implementation, architecture and design of APL in Common Lisp, as well as code that combines APL and Lisp to create visualisations. He showed a visualisation that used APL to both run Conway’s Game of Life and apply convolution kernels to show the state of cells over time. We loved seeing how he has been using April in the visual art installation Bloxl (a collection of computer-controlled light-up blocks used at events for a stunning visual effect). Andrew concluded his presentation with a demonstration of April code implementing a “falling block game”, and a video of that game in action.
Andrew gives a comparative overview of the histories of the APL and Lisp programming languages
Finally, there was a live recording of an episode of Array Cast, a semi-weekly podcast about array languages. From the regular panel of presenters were self-proclaimed J enthusiast Bob Therriault, Kx Librarian Stephen Taylor, Dyalog tools developer and life-long APL programmer Adám Brudzewsky, and professional C++ developer and programming language fanboy Conor Hoekstra. They were joined by a very special panel of guests: speakers from the event Gitte Christensen, Rich Park, Stefan Kruger, and Andrew Sengul, and well-known APLers Aaron Hsu and Rodrigo Girão Serrão.
The discussion began with the common beginners’ questions of keyboards, typing APL and whether you really need stickers, keycaps or a whole dedicated APL keyboard to use APL. On the topic of actually learning APL, there were mentions of even more books and other resources, including YouTube channels run by some of the podcast panellists and guests. All relevant links are included in the show notes for the episode, and you can listen to the episode on arraycast.com.
Taking a more technical turn, there was discussion of the balance between code clarity and performance. Should code be clear unless absolutely performance critical? Or is it possible to have both, where the clearer encodings and approaches are also the fastest? The episoded was capped off nicely, in response to a question from the audience, with Gitte offering her perspective on how APL can help a data analyst or engineer.
In the informal meet-up after the talks, Andrew configured a simple interface to the aforementioned “falling block puzzle game”, in which participants could control the game and see their moves played out on a Bloxl wall streamed in real (if a bit delayed) time. The players tried their best but were ultimately thwarted by the interface of clicking buttons using Zoom shared controls!
To those who attended, we hope you found the event enjoyable. Relevant materials have been uploaded to the APL Seeds ’22 webpage, including links to recordings of the presentations on dyalog.tv.
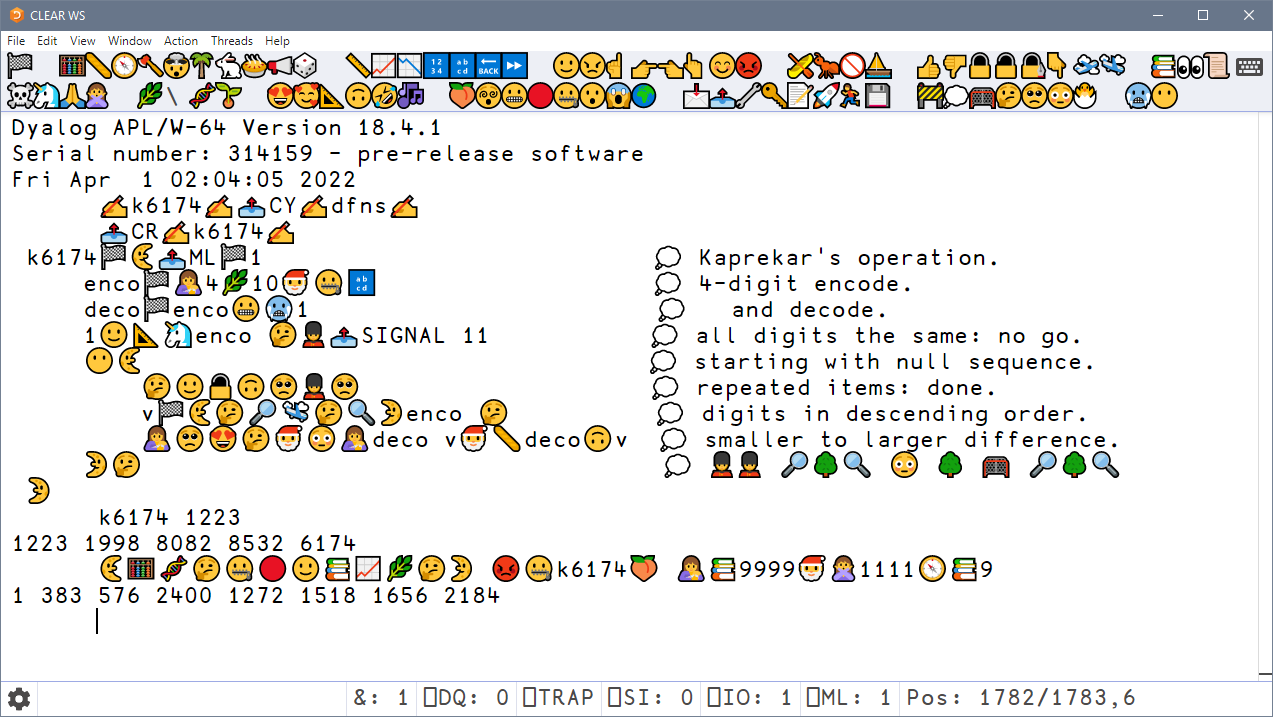
During the recent APL Seeds ’22 meeting, it was suggested that we introduce keywords that could be used as an alternative to APL symbols. Several historical APL systems have provided such mechanisms. However, rather than adopting one of the old keyword schemes, we have decided to go for a more future-proof solution, recognising that the modern equivalent of keywords is emojis.
Emojis are already in widespread usage: they are included in fonts, and there is support for entry of emojis on a wide variety of devices. We have decided to adopt the existing proposal by StavromulaBeta, with minor changes. Examples include:
New Emoji
Legacy Glyph
New Emoji
Legacy Glyph
?
⍵
?
⍝
✍
'
?
←
?
:
?
⎕
?
(
?
)
?
{
?
}
In addition to usage of the language bar, and platform-specific emoji input methods, input via emoticons like :) and shortcodes like :slightly_smiling_face: (as used in chat clients and on GitHub, respectively), can be toggled on.
Screen-shot of a representative 18.4.1 sample session.
Backwards compatibility will be provided by an automatic translation mechanism on )LOAD of existing workspaces, and Link will update all source files, on first use of the new version 18.4.1.
For users of the Classic edition, new ⎕Uxxxxx spellings will be introduced. For example, the last expression in the above screen-shot will be:
Unfortunately, we are not able to make the new version available on the Apple macOS® platform, where the use of a certain of fruit emoji makes it impossible to introduce the new spelling.
We will be announcing the release date for version 18.4.1 shortly. Please contact support@dyalog.com if you would like to participate in testing the pre-release, or have suggestions for improving the choice of emojis.
By: Stefan Kruger Stefan works for IBM making databases. He tries to learn at least one new programming language a year, and a few years ago he got hooked on APL and participated in the competition. This is his perspective on some solutions that the judges picked out – call it the “Judges’ Pick”, if you like; smart, novel, or otherwise noteworthy solutions that can serve as an inspiration.
Congratulations to all the winners of the 2021 APL Problem Solving Competition (you can learn more about the phase 2 winners in this article) and well done to Dzintars Klušs who won the Grand Prize. At the recent Dyalog ’21 user meeting, we got to enjoy the runner-up, Victor Ogunlokun, walking us through his solutions live.
In this post I’ll go through some great solutions that were submitted (and some that weren’t submitted) to the Phase I problems so that we can all marvel in the ingenuity and perhaps learn a thing or two. If you’re feeling inspired by the end, go ahead and participate in this year’s round which just launched.
If you’re new to the APL Problem Solving Competition, Phase I problems tend to be short and the expectation is that solutions will be “one-liners” (dfns). However, although it might seem like it from some of the solutions here, this isn’t a code golf competition! Solutions are judged holistically: do they solve the problem, are they efficient, and are they clear? Even though a few test cases are given, there is no guarantee that your solution is correct just because it works for the example data. The judging process involves running the code on many hidden test cases too. Crucially, just because your code is accepted, it doesn’t necessarily mean that you’ll get full marks.
Something from the excellent Project Rosalind problem collection, the task is to compute the combined percentage of guanine (G) and cytosine (C) in a given DNA-string.
Efficiency can vary a lot, depending on whether summation or multiplication (or even division!) is performed first. Some solutions were also leading-axis oriented.
Here’s my solution:
{100×(+⌿⍵∊'CG')÷≢⍵} 'ACGTACGTACGTACGT'
50
which several competitors made more tacit with:
{100×(+⌿÷≢)⍵∊'GC'} 'ACGTACGTACGTACGT'
50
or even went further:
(100×≢÷⍨1⊥∊∘'GC') 'ACGTACGTACGTACGT'
50
If you’re unfamiliar with the 1⊥ trick, it’s a way of summing a vector:
1⊥6 3 9 8 12 62
100
It’s perhaps not immediately obvious why this should work. Here’s one explanation. Assume we want to sum the vector 1 0 2 0 0. We can do this in a very convoluted way by using a sum inner product with a vector of exponentials: [14, 13, 12, 11, 10]:
(1*4 3 2 1 0)+.×1 0 2 0 0
3
If we expand the exponentials to the left we get a vector of 1s. We can then break apart the inner product by turning +. to a +⌿ to the left:
+⌿1 1 1 1 1×1 0 2 0 0
3
This is the textbook definition of 1⊥! Look:
1⊥1 0 2 0 0
3
which, to be clear, is just the sum-reduce-first:
+⌿1 0 2 0 0
3
Using 1⊥ to sum has two advantages over the more obvious formulation +⌿. Firstly, it’s easier to use in tacit formulations as it doesn’t require an operator, and secondly, it’s usually faster. The reasons for it being quicker is somewhat beyond the scope of this post, but it’s to do with 1⊥ making no guarantees about the ordering of operations, meaning that the interpreter is free to vectorise more efficiently.
Problem 2: Index-Of Modified
This problem wanted us to write a function that behaves like the APL Index Of function R←X⍳Y except that it should return 0 for elements of Y not found in X.
I wrote:
p2 ← {0@((≢⍺)∘<)⊢⍺⍳⍵}
2 3 p2 ⍳5
0 1 2 0 0
which is basically saying “change all instances of numbers greater than the length of the argument to zero”, which is how X⍳Y presents values that are not found.
Some very different solutions were submitted, for example:
p2 ← ⍳|⍨1+≢⍤⊣
2 3 p2 ⍳5
0 1 2 0 0
which is simply:
p2 ← {(1+≢⍺)|⍺⍳⍵} ⍝ dfn of the above
2 3 p2 ⍳5
0 1 2 0 0
Another option would have been to multiply ⍺⍳⍵ with ≢⍺, although no-one submitted exactly this:
p2 ← ≢⍤⊣(≥×⊢)⍳
2 3 p2 ⍳5
0 1 2 0 0
which could have been written explicitly as:
p2 ← {m×(≢⍺)≥m←⍺⍳⍵} ⍝ dfn of the above
2 3 p2 ⍳5
0 1 2 0 0
Problem 3: Multiplicity
Write a function that:
has a right argument Y which is an integer vector or scalar
has a left argument X which is also an integer vector or scalar
finds which elements of Y are multiples of each element of X and returns them as a vector (in the order of X) of vectors (in the order of Y).
although no-one actually submitted that, to everyone’s credit.
Problem 4: Square Peg, Round Hole
Write a function that:
takes a right argument which is an array of positive numbers representing circle diameters
returns a numeric array of the same shape as the right argument representing the difference between the areas of the circles and the areas of the largest squares that can be inscribed within each circle.
I had to read that many times before it sank in. The key to achieve something snappy is to really work through the maths until it is as compact as possible, which, if you’re anything like me, you didn’t bother to do.
My attempt was:
p4 ← {(○2*⍨⍵÷2)-2÷⍨⍵*2}
but there are much neater solutions if you did your homework. Here’s one that no-one found:
p4 ← (○-+⍨)4÷⍨×⍨
and a nice explicit version:
p4 ← {⍵×⍵×0.5-⍨○÷4}
which can be derived from this simplified mathematical expression, suggested by Rodrigo:
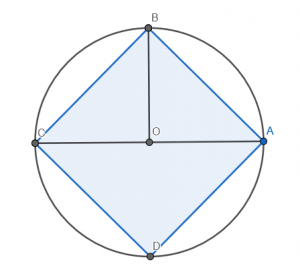
Explanation: The area of the circle is ○r*2, which is ○(⍵÷2)*2, in turn equivalent to ⍵×⍵×○÷4. The area of the square [ABCD] is twice the area of the triangle [ABC]. Given that the area of the triangle is 0.5×⍵×⍵÷2, the area of the square becomes 0.5×⍵×⍵. Putting both together, we get (⍵×⍵×○÷4)-⍵×⍵×0.5, the same as ⍵×⍵×(○÷4)-0.5, which is ⍵×⍵×0.5-⍨○÷4.
Problem 5: Rect-ify
For this problem, we were asked to plant a number of trees in a rectangular pattern with complete rows and columns, meaning all rows have the same number of trees. That rectangular pattern also needed to be as “square as possible”, meaning there is a minimal difference between the number of rows and columns in the pattern.
Here’s a smart solution, based on the observation that the “most square” choice must have one factor being the largest factor less than or equal to the square root:
p5 ← {N,⍵÷1⌈N←⌈/0,⍵∨⍳⌊⍵*÷2}
This solution works well on large numbers of trees, too:
So is one solution better than the other? Well, they both work correctly, but one is a lot faster than the other. Do you want to guess which was faster before we test it?
Surprised? I was! So, what is going on here? The non-recursive solution relies on a rather crude way to find the factors, which is a fairly large number to factorise even if it only needs to go up to the square root. The recursive version just tries each number in turn, up to the square root.
Can we be even smarter? This version was offered up by APL Orchard regular @rak1507:
Basically, (⊢∨⍳) is neat as a code-golf trick, but not great in terms of efficiency.
Problem 6: Fischer Random Chess
According to Wikipedia, Fischer random chess is a variation of the game of chess invented by former world chess champion Bobby Fischer. Fischer random chess employs the same board and pieces as standard chess, but the starting position of the non-pawn pieces on the players’ home ranks is randomised, following certain rules.
White’s non-pawn pieces are placed on the first rank according to the following rules:
the Bishops must be placed on opposite-colour squares
the King must be placed on a square between the rooks.
The task was to write a function that verifies that a given board placement is valid according to these rules.
This was my solution for this:
q6 ← {(1=+/(⍵⍳'K')>⍸'R'=⍵)∧1=+/2|⍸'B'=⍵}
but there was a lot of variety in the solutions submitted to this problem. For example:
q6i ← {≠/2|⍸'B'=⍵}∧'RKR'≡∩∘'RK' ⍝ Intersection
q6ii ← {(≠/2|⍸'B'=⍵)∧1=(⍸'R'=⍵)⍸⍵⍳'K'} ⍝ Interval index
q6w ← {(≠/2|⍸'B'=⍵)∧≠/(⍸'K'=⍵)<⍸'R'=⍵} ⍝ Where (similar to mine above)
The fork ⍉,[0.5]⌽ takes the argument matrix – a square array of rank-2, shape A A – and returns an array of rank-3, shape 2 A A, where the first cell is the transposed original array and the second is the original array with its rows reversed:
We only need to know about the main diagonal of each cell; as you can see, the main diagonal in the second cell is the reverse diagonal of the first cell. We can extract both diagonals with a single dyadic transpose:
1 2 2⍉(⍉,[0.5]⌽) magic
4 5 6
2 5 8
The same result can be achieved using slightly less showy ⍤ instead, which has the same byte count but is a little easier to understand when first seen:
1 1⍉⍤2(⍉,[0.5]⌽) magic ⍝ Diagonals of each major cell love ⍤
4 5 6
2 5 8
The remaining part of the tacit formulation untangles easily. Impressive and creative.
{1=≢∪+⌿⍵,⍥{(1 1⍉⍵),⍵}⌽⍵} magic ⍝ Length of vector of unique values = 1?
1
In summary, there are two things to note here: using ⍥ to get both diagonals and the use of 1=≢∘∪ to check that all items are equal. If you attended the APL Seeds ’21 conference last March, you’ll recognise this as one of the many ways of solving this problem that Conor Hoekstra presented – see https://dyalog.tv/APLSeeds21/?v=GZuZgCDql6g to watch his presentation.
Any solution that makes use of both of my favourite glyphs (⍤ and ⍥) is a winner in my book.
Problem 8: Time to Make a Difference
Write a function that:
has a right argument that is a numeric scalar or vector of length up to 3, representing a number of [[[days] hours] minutes] – a single number represents minutes, a 2-element vector represents hours and minutes, and a 3-element vector represents days, hours, and minutes
has a similar left argument, although not necessarily the same length as the right argument
returns a single number representing the magnitude of the difference between the arguments in minutes.
Here’s a cool version (several submissions were similar):
p8 ← |-⍥(1 24 60⊥¯3∘↑)
Nothing too mysterious here. A slight complication is the need to handle a right argument that can be a scalar or a vector of length 2 or 3. The decode function ⊥ expects the argument vector to always be length 3, so we use the take function, dyadic ↑, with ¯3 as the left argument to ensure that the argument is always a vector of the correct length, padding from the left with zeros as required. The mixed radix vector 1 24 60 as the left argument to decode converts to minutes.
Problem 9: In the Long Run
Write a function that:
has a right argument that is a numeric vector of 2 or more elements representing daily prices of a stock
returns an integer singleton that represents the highest number of consecutive days where the price increased, decreased, or remained the same, relative to the previous day.
I’d like to compare and contrast two solutions, neither of which are tacit for a change:
Starting with the first of the two (p9a), from the right, we use a windowed difference reduction to calculate pairwise differences:
2-/1 3 5 6 6 6 6 6 3 2 1
¯2 ¯2 ¯1 0 0 0 0 3 1 1
and then apply the direction function, monadic ×, to turn this into a vector of ¯1, 0 and 1 if the corresponding item is negative, zero or positive respectively:
×2-/1 3 5 6 6 6 6 6 3 2 1
¯1 ¯1 ¯1 0 0 0 0 1 1 1
Another pairwise windowed reduction, this time with ≠, gives us the points of change:
2≠/×2-/1 3 5 6 6 6 6 6 3 2 1
0 0 1 0 0 0 1 0 0
Prepending a 1, this Boolean vector can be used as the left argument to partitioned enclose, ⊂; a common pattern. But what of the right argument? We can use the same vector as the right argument by using a clever commute, ⍨:
⊢m←⊂⍨1,2≠/×2-/1 3 5 6 6 6 6 6 3 2 1 ⍝ Commute to use the same argument left and right
┌─────┬───────┬─────┐
│1 0 0│1 0 0 0│1 0 0│
└─────┴───────┴─────┘
What remains is to find the longest cell in this vector. We could do ⌈/≢¨, but instead this submission found the length of the transpose-mix:
≢⍉↑ m
4
A code-golfer’s trick shot, perhaps, and somewhat dubious in terms of efficiency, but certainly cute. If you don’t see why it works, work it through right to left!
The second solution (p9b) uses a lot of the same ideas, but this time we add a 1 to the end of the points-of-change vector:
and use where, monadic ⍸, to get the indices, prepending a 0 so that we can calculate the length of each segment:
{0,⍸1,⍨2≠/×2-/⍵}1 3 5 6 6 6 6 6 3 2 1
0 3 7 10
The pairwise difference now represents the length of each segment, and by using a negative window we can commute each pair to get a positive number out for each pair:
{¯2-/0,⍸1,⍨2≠/×2-/⍵}1 3 5 6 6 6 6 6 3 2 1
3 4 3
and so, for the maximum:
{⌈/¯2-/0,⍸1,⍨2≠/×2-/⍵}1 3 5 6 6 6 6 6 3 2 1
4
Shall we race them? Of course!
data ← 10000?10000
cmpx 'p9a data'
p9a data → 2.7E¯4 | 0% ⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕⎕
p9b data → 2.1E¯5 | -92% ⎕⎕⎕
The second version is faster for several reasons. We suspected already that the ‘cute’ way to find the longest vector in a nested vector was likely to be slow, as it has to create a huge matrix first, chasing pointers. The second version uses flat numeric vectors throughout, and cuts the work considerably by using where initially to do length calculations on the shorter vector of indices. Flat is fast.
Problem 10: On the Right Side
Write a function that:
has a right argument T that is a character scalar, vector or vector of character vectors/scalars
has a left argument W that is a positive integer specifying the width of the result
returns a right-aligned character array R of shape ((2=|≡T)/≢T),W meaning that R is one of the following:
a W-wide vector if T is a simple vector or scalar
a W-wide matrix with the same number rows as elements of T if T is a vector of vectors/scalars
if an element of T has length greater than W, truncate it after W characters.
The last point is perhaps a bit misleading, but the intention is clear from one of the examples given:
In this case, “truncate after W characters” means “remove from the left”.
Conceptually, we need to (over)take W characters from the right of each element and mix that into a rank-2 array. To make it work for the edge cases, we should ensure that we can always treat the right argument as a vector of character vectors, using nest, monadic ⊆. This works because if we take more characters than the vector contains, it gets padded using a character-vector’s prototype element, a space.
8 {↑(-⍺)↑¨⊆⍵} 'Longer Phrase' 'APL' 'Parade'
r Phrase
APL
Parade
An equivalent tacit formulation would be:
8 (↑-⍤⊣↑¨⊆⍤⊢) 'Longer Phrase' 'APL' 'Parade'
r Phrase
APL
Parade
Here’s a slight variation:
8 {⌽⍉⍺↑⍉↑⌽¨⊆⍵}'Longer Phrase' 'APL' 'Parade'
r Phrase
APL
Parade
This starts by reversing each cell, then applies a mix and transpose. We then take items from the left before backing out of the transpose and reverse by applying them again.
It can be done in a flatter manner, too:
8{⍉(-⍺)↑⍉(⊆⍵)⌽∘↑⍨(⊢-⌈/)≢¨⊆⍵} 'Longer Phrase' 'APL' 'Parade'
r Phrase
APL
Parade
If we flip the selfie and add a few spaces it gets a bit easier to see what’s going on:
From the right, we turn our input into a character array and then Rotate each row by its length minus the length of the longest row, which implements the right alignment:
The complex, flat version wins, but not by a significant amount.
With that we’ve reached the end. A nice set of problems, with a lot of creative solutions submitted. Watch this space for a review of the Phase II problems…




 Follow
Follow